AI-Powered Resume Analyzer & Ranker
Real-time AI agent to analyze, rank, and improve resumes using AI models
Project Overview
This project offers a smart resume screening system that leverages AI and LLM-powered RAG agents to score and evaluate resumes against job descriptions in real-time. With support for PDF/DOCX/TXT uploads, skill-matching insights, batch ranking, and personalized feedback generation (with downloadable PDF reports), it simulates a virtual recruiter. The solution includes two Streamlit-based apps: one for end-to-end AI scoring and RAG feedback, and another with agentic querying for resume insights.


Objective & Business Context
Hiring and job applications are often plagued by inefficiencies: recruiters struggle to filter high volumes of resumes, and candidates rarely receive constructive feedback on why their applications were rejected or underperforming. This gap results in lost time, poor matches, and missed opportunities on both sides.
This project aims to bridge that gap using AI.
Primary Objectives:
Analyze resumes in real-time using local NLP pipelines.
Match resumes against a provided Job Description (JD) using interpretable scoring methods.
Generate AI-driven improvement suggestions using LLMs.
Enable batch processing and rank ordering of multiple resumes.
Provide downloadable PDF feedback to share with candidates or archive.
User Personas Served:
Recruiters & Hiring Managers (manual screening at scale)
Job Applicants (self-evaluation before submitting)
Career Coaches and Institutions (bulk feedback and recommendations)
Business Value and Real-World Scope
This solution directly contributes to smarter, faster, and fairer hiring workflows. With increasing adoption of AI in HR tech, having explainable and locally-run tools helps reduce bias, increase transparency, and improve candidate experience.
Real-World Benefits:
Recruitment Automation: Faster shortlisting of qualified applicants.
Candidate Experience: Feedback that helps applicants improve.
Internal Mobility: Rank internal candidates against posted roles.
University Career Cells: Batch evaluation of student resumes.
Privacy-Focused Enterprises: No reliance on 3rd party APIs; fully local.
The project scales easily into SaaS tools, internal ATS plugins, or academic feedback tools.
Implementation Flow
This solution operates in two primary workflows:
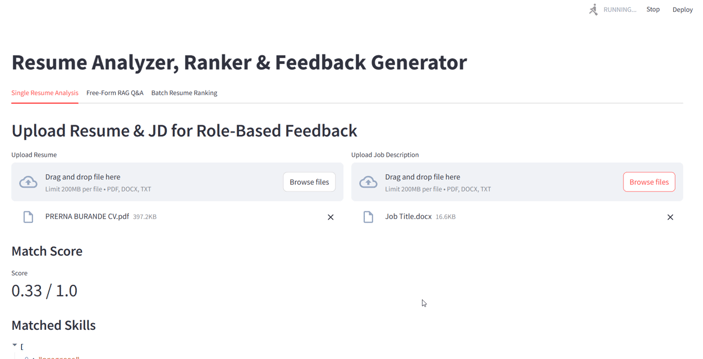
A. Single Resume + JD Flow
User Uploads Files: PDF/DOCX resume and JD.
Text Extracted: Using PyMuPDF and docx2txt (or EasyOCR fallback).
Resume Scoring: TF-IDF vectorizer with cosine similarity.
Role-Based Prompt Creation: Job role inferred from JD filename.
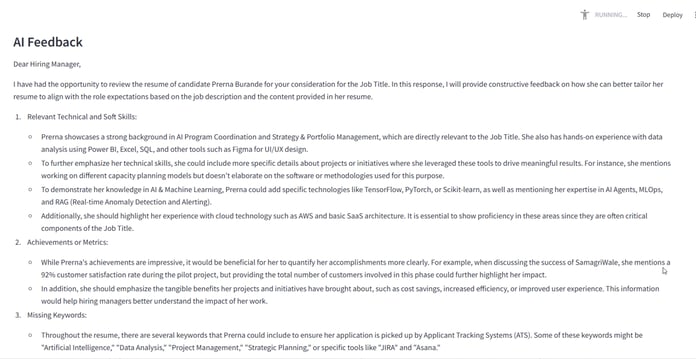
RAG + LLM Agent: Resume vectorized with FAISS; feedback generated by Mistral via LangChain RetrievalQA.
Insights Displayed: Score, skills matched, detailed feedback.
PDF Download: A printable feedback summary using FPDF.
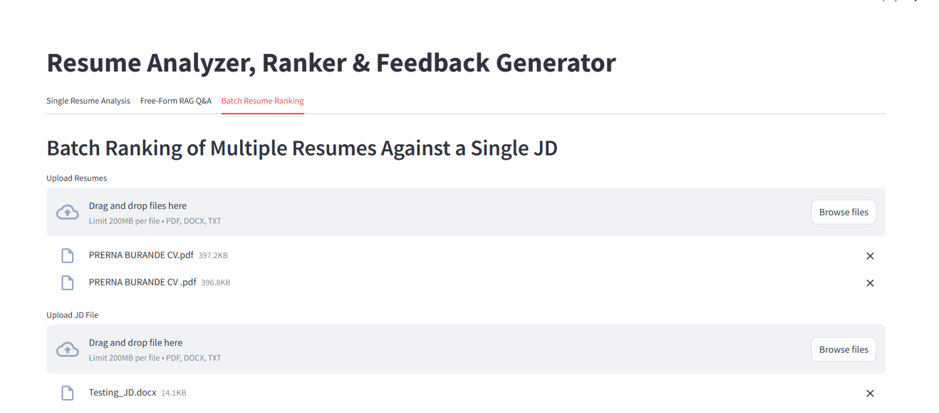
B. Batch Resume Ranking Flow
Upload JD + Multiple Resumes: Via Streamlit multi-upload interface.
Loop Execution: For each resume:
Extract text
Score against JD
Run RAG agent for feedback
Save feedback PDF
Ranking Table: Match scores are sorted; ranks shown.
Batch Output: All results saved in CSV; individual feedback PDFs available.
Dataset Overview
Supported Input Files
Resumes: .pdf, .docx, .txt, image-based (via OCR)
Job Descriptions: .pdf, .docx, .txt
A. Real-Time Resume Analysis
Text extraction: PyMuPDF, DOCX parser, EasyOCR
Comparison: Cosine similarity on TF-IDF vectors
B. Resume Scoring Logic
Tfidf Vectorizer applied to Resume + JD
Similarity score (0.0 to 1.0)
Token overlap used to highlight skill matches
C. LLM-Based Feedback Generation
Uses LangChain with Mistral-7B via Ollama backend
Persona-based prompt creation (e.g., "for AI Product Manager")
LLM generates improvement suggestions (missing skills, phrasing, alignment)
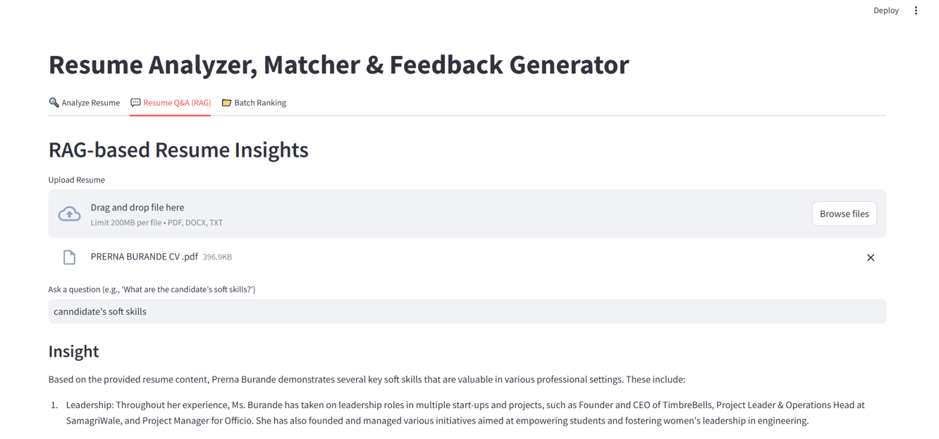
D. RAG Agent for Deeper Analysis
Embeds resume using Ollama Embeddings
Uses FAISS to store document chunks
LangChain RetrievalQA combines query + context + LLM
E. Batch Ranking & Reporting
Multi-resume upload interface
Ranks resumes based on score (1st, 2nd, etc.)
PDF feedback report for each resume
Core Features & Technical Workflows
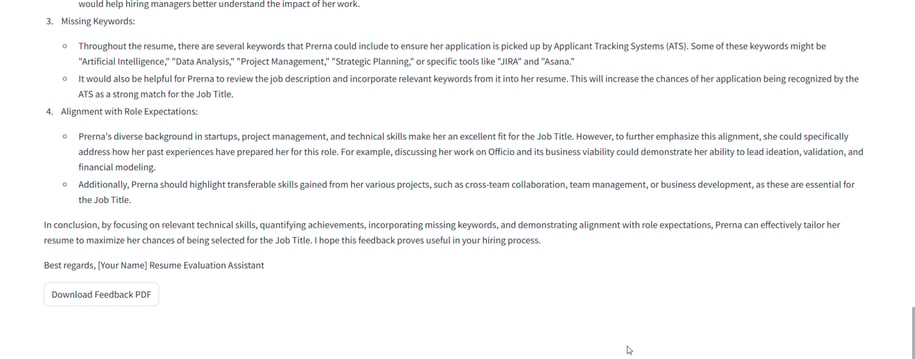


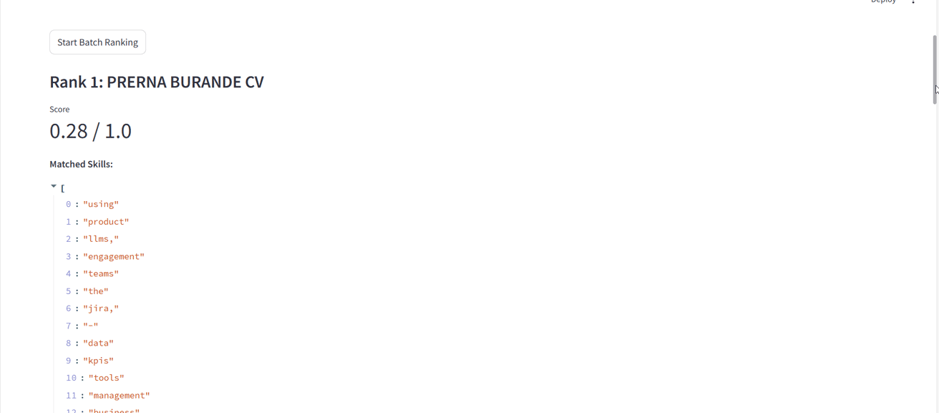
✅ Resume Match Score – Numerical similarity score (e.g., 0.85 / 1.0) between resume and job description.
✅ Matched Skills – Keyword overlap shown to highlight skill alignment.
✅ AI-Powered Feedback – Generated using persona-specific prompts via Mistral LLM.
✅ Downloadable Feedback PDF – One-click export of resume-specific suggestions in report format.
✅ Rank Visualization – Clear 1st, 2nd, 3rd… rankings for batch resume uploads.
✅ RAG-Based Q&A Agent – Interactive query answering using resume content and vector embeddings.
✅ Support for Scanned Documents – Image-based resumes parsed with OCR for inclusive access.
✅ Fully Local Execution – All processing and models run offline with no third-party API usage.
Key Deliverables
Tools and Libraries Used
pandas – Data manipulation, cleaning, loading CSV files
numpy – Mathematical computations and array handling
scikit-learn – TF-IDF vectorization, cosine similarity
PyMuPDF (fitz) – PDF parsing
docx2txt – Word document parsing
pdf2image + EasyOCR – OCR fallback for scanned resumes
fpdf – PDF feedback generation
streamlit – Web interface for real-time resume analysis
LangChain – Prompt chaining, RetrievalQA agent setup
FAISS – Local vector search store for RAG-based feedback
Ollama – Local LLM runtime using the Mistral-7B model
tempfile & tkinter – File system access for local batch processing
Add cover letter analysis alongside resume matching.
Allow comparison of a single resume against multiple job descriptions.
Introduce feedback personalization based on industry or seniority level.
Integrate scoring matrix customization (e.g., weight certain skills more).
Improve batch performance with asynchronous or queued processing.
Extend PDF reports with visuals like radar charts or skill maps.
Deploy as a desktop app or lightweight Docker-based local service.
Enable user accounts and resume history for recurring usage.
Possible Next Steps & Conclusion
Conclusion
This project blends GenAI, NLP, and user-centric design into a powerful, local-first resume screening assistant. By combining TF-IDF scoring with LLM-powered feedback, it achieves the dual goal of automation and personalization — improving hiring efficiency while empowering job seekers.
The solution is flexible enough to be deployed offline, adapted for SaaS models, or embedded into enterprise ATS systems. It also shows the potential of using lightweight open models like Mistral for impactful HR tooling — free from vendor lock-in or expensive API costs.
From single uploads to batch screening, it delivers a modern, explainable way to review resumes — with transparency, speed, and AI intelligence.
Dive into the foundational concepts, algorithms, and real-world relevance behind this project. From machine learning principles to business strategy insights, this conceptual study bridges the gap between technical implementation and applied decision-making—helping you understand not just how it works, but why it matters.
Key Concepts
GitHub Repository
Want to dive deeper into how this project actually works?
We’ve made the complete codebase and resources available for you on GitHub
👉 Access the full repository here:
Whether you're a learner, recruiter, or collaborator — there's something for everyone.
Connect
Join us in shaping the future of leadership.
Innovate
contact@youlead.com
© 2025. All rights reserved.